
本文主要介绍leveldb的put流程。
- 整体架构
- LOG文件
- Put流程
整体架构
整体架构主要从静态角度来描述。
所谓的静态角度,我们可以假想整个存储系统正在运行过程中(不断插入删除读取数据),此时我们给LevelDb照相,从照片可以看到之前系统的数据在内存和磁盘中是如何分布的,处于什么状态等等;
从动态的角度,主要是了解系统是如何写入一条记录,读出一条记录,删除一条记录的,同时也包括除了这些接口操作外的内部操作比如compaction,系统运行时崩溃后如何恢复系统等等方面。
LevelDb作为存储系统,数据记录的存储介质包括内存以及磁盘文件,如果像上面说的,当LevelDb运行了一段时间,此时我们给LevelDb进行透视拍照,那么你会看到如下图的景象
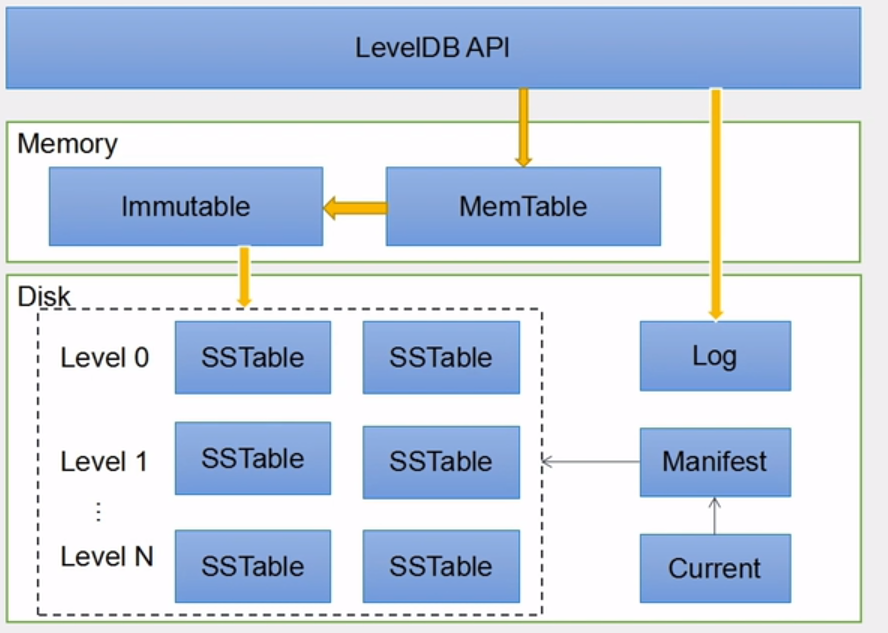
当应用写入一条Key:Value记录的时候,LevelDb会先往log文件里写入,成功后将记录插进Memtable中,这样基本就算完成了写入操作,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,所以这是为何说LevelDb写入速度极快的主要原因。
SSTable 就是由内存中的数据不断导出并进行 Compaction 操作后形成的,而且 SSTable 的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDb的原因。
在图中我们可以看到,内存中有MemTable, Immutable memtable,磁盘中有LOG文件,Manifest文件,Current文件,以及SSTable。这些文件或者内存结构在后续的文章中会详细介绍。本文介绍Put流程,就先介绍LOG文件
LOG文件
首先请看LOG文件相关的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
namespace leveldb {
namespace log {
enum RecordType {
// Zero is reserved for preallocated files
kZeroType = 0,
kFullType = 1,
// For fragments
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
};
static const int kMaxRecordType = kLastType;
static const int kBlockSize = 32768;
// Header is checksum (4 bytes), length (2 bytes), type (1 byte).
static const int kHeaderSize = 4 + 2 + 1;
} // namespace log
} // namespace leveldb
LOG文件在leveldb中的主要作用是系统故障恢复时,能够保证不会丢失数据。因为在将记录写入内存的Memtable之前,会先写入LOG文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据LOG文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据,在这点上LevelDb和Bigtable是一致的。(PS:实际代码实现时,p写文件也可以通过参数控制是立马刷盘还是交由操作系统自行控制,也就是说交由系统控制的话,也是可能会存在丢数据的情况)
通过上面的代码可以看出LOG文件的物理布局就是由连续的 32K 大小 Block 构成的。
物理布局如下图:
在应用的视野里是看不到这些Block的,应用看到的是一系列的Key:Value对,在leveldb内部,会将一个Key:Value对看做一条记录的数据,另外在这个数据前增加一个记录头,用来记载一些管理信息,以方便内部处理,下图显示了记录头的结构: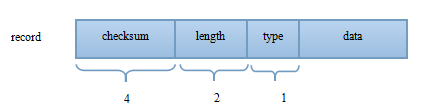
1 | checksum: uint32 // type及data[]对应的crc32值 |
类型存在4种:
kFullType : 顾名思义记录完全在一个block中
kFirstType : 当前block容纳不下所有的内容,记录的第一片在本block中
kMiddleType : 记录的内容的起始位置不在本block,结束未知也不在本block
kLastType : 记录的内容起始位置不在本block,但 结束位置在本block
PUT流程
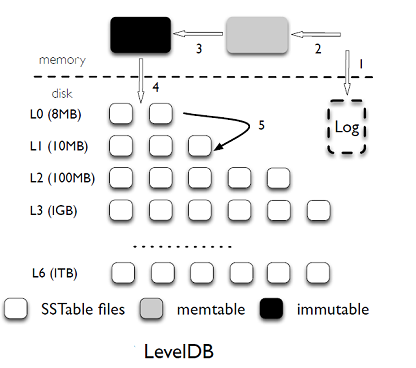
简单的说:其实PUT流程就两步,一写LOG, 二写(插入)memtable:
- 数据首先会被写到 log,保证持久性;
- 然后写入 mutable memtable 中,返回;
- 当 mutable 内存到达一定大小之后就会变成 immutable memtable;
- 当到达一定的条件后,后台的 Compaction 线程会把 immutable memtable 刷到盘中 Level 0 中 sstable;
- 当 level i 到一定条件后,就会和 level i+1 中的 sstable 进行 Compaction,合并成 level i+1 的 sst 文件
调用栈
主要调用顺序大体就3步:1
DBImpl::Put -> DB::Put -> DBImpl::Write
1 | Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
先生成一个Writer,然后抢一个mutex锁,多线程的写入会在这里互斥,只能有一个进来,第一个进来的写操作会在真正写log文件和写memtable的时候把锁放掉,这时候别的写操作会进来把自己push到writes_的deque中,然后睡在自己的条件锁上,因为此时自己的done不是true并且自己不是deque中的第一个writer。等第一个writer全部操作完之后呢,会把此时deque中的所有writer唤醒,这里可能要问了,为什么醒了之后第一步是判断自己是不是done呢,自己还没执行怎么可能会done呢,其实这是leveldb的优化,当前抢到锁进来的writer会在真正操作之前把此时deque中所有的writer的任务都拿过来(实际上不是全拿过来,有数量限制,在BuildBatchGroup函数中有明确的过程),然后一起做了,并且把结果放回至每个writer对应的status中,最后再唤醒所有writer,所以这些writer醒来后发现自己的任务已经被做了,就直接拿自己的返回值返回了。
另外值得一提的是,条件变量与互斥锁之间的使用,直接上代码:1
2
3
4
5
6
7
8
9
10struct DBImpl::Writer {
explicit Writer(port::Mutex* mu)
: batch(nullptr), sync(false), done(false), cv(mu) {}
Status status;
WriteBatch* batch;
bool sync;
bool done;
port::CondVar cv;
};
就是代码中传入了互斥锁mu,如果不传这个的锁,会出现多线程中一个容易犯的问题:唤醒丢失问题,具体可以参考条件变量 之 稀里糊涂的锁
写入前检查:MakeRoomForWrite1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61Status DBImpl::MakeRoomForWrite(bool force) {
mutex_.AssertHeld();
assert(!writers_.empty());
bool allow_delay = !force;
Status s;
while (true) {
if (!bg_error_.ok()) {
// Yield previous error
s = bg_error_;
break;
} else if (allow_delay && versions_->NumLevelFiles(0) >=
config::kL0_SlowdownWritesTrigger) {
// We are getting close to hitting a hard limit on the number of
// L0 files. Rather than delaying a single write by several
// seconds when we hit the hard limit, start delaying each
// individual write by 1ms to reduce latency variance. Also,
// this delay hands over some CPU to the compaction thread in
// case it is sharing the same core as the writer.
mutex_.Unlock();
env_->SleepForMicroseconds(1000);
allow_delay = false; // Do not delay a single write more than once
mutex_.Lock();
} else if (!force &&
(mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) {
// There is room in current memtable
break;
} else if (imm_ != nullptr) {
// We have filled up the current memtable, but the previous
// one is still being compacted, so we wait.
Log(options_.info_log, "Current memtable full; waiting...\n");
background_work_finished_signal_.Wait();
} else if (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) {
// There are too many level-0 files.
Log(options_.info_log, "Too many L0 files; waiting...\n");
background_work_finished_signal_.Wait();
} else {
// Attempt to switch to a new memtable and trigger compaction of old
assert(versions_->PrevLogNumber() == 0);
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = nullptr;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
MaybeScheduleCompaction();
}
}
return s;
}
写入检查流程可以归结为下图: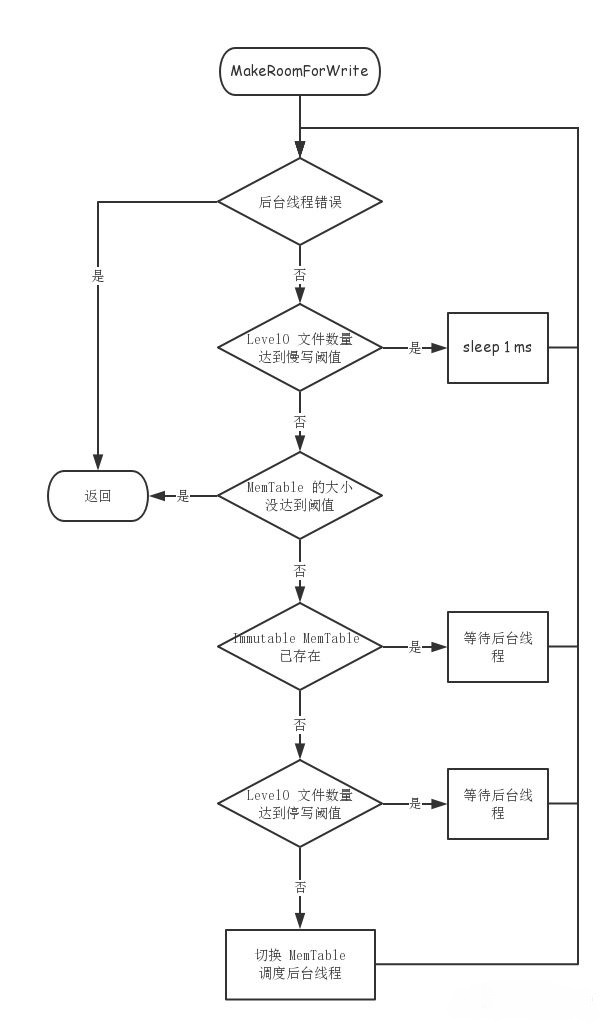
关于PUT流程暂且写这么多,如果想了解更多可以阅读参考资料。
参考资料:
数据分析与处理之二(Leveldb 实现原理)
LevelDb 源码阅读–写操作
Leveldb之Put实现
条件变量 之 稀里糊涂的锁

